
Utility Barriers for AI Assistance in Knowledge Work
In which we try to extrapolate if the step-change in AI assistance utility currently experienced by computer programmers can be expected by other fields.

A few days ago at dinner, my friend Aaron asked me whether I felt there was something special and non-transferable about AI assistance for coding or if we should expect the same kind of step-change transformation we are observing there to eventually spread to all knowledge work.
My gut told me that coding is special and I would be very surprised if the same utility step-change we are experiencing in programming ends up applying to all other kinds knowledge work.
In this post, I try to explain why.
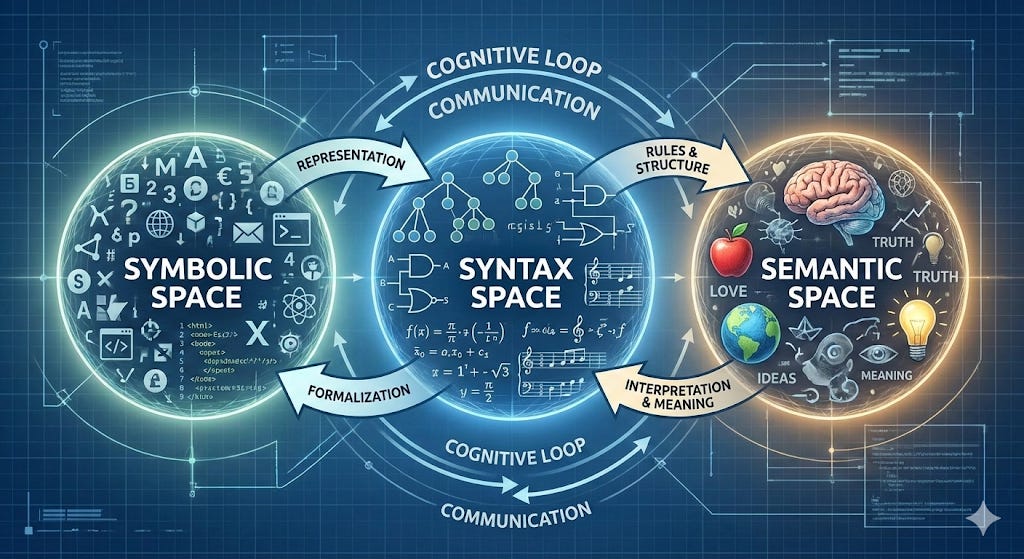
Cognitive Spaces
Let’s start by defining a cognitive space as a plane in which we can focus our cognitive attention. I believe there are three different of such spaces involved in computer programming:
the symbol space is the space in which the machine itself operates (at least at a high level). It is made of things like registers, instructions, memory addresses, stacks. We can program machines at this level (using “assembly” languages) and each “machine architecture” (x86, ARM, Sparc, etc.) has different instruction sets, which requires different symbols.
the syntax space is the space we generally think of as “coding” or “programming” and it’s made of the syntax of programs written in programming languages such as C, C++, C#, Java, Python, Rust, Javascript, Typescript, PHP, Perl, Lisp, Scheme, Prolog, Fortran, Cobol, Algol, Erlang, Ocaml, Haskel and on and on and on.
the semantic space is the space of box diagrams, flowcharts, sequence diagrams, entity-relationship models, design patterns, algorithms and very high level programming concepts.
The Syntax → Symbol Bridge
The first big revolution in computing was the creation of “compilers” or “interpreters” which allowed humans to operate in syntax space and have machines do the work to translate those programs to symbol space.
This was groundbreaking for several reasons:
it was a lot easier for humans to operate in syntax space than in symbol space. It’s a lot easier to think of an “if/then” conditional or a “for” loop than to deal with the machine instructions, register and memory allocations the underlying CPU needs to be executing to implement those higher level operations.
it was a lot easier for a human to understand what the computer was doing when reading code at higher level. It is hard to understand if something is a for loop or a conditional when we’re just focusing on what goes in and out of registers and makes program jumps to different memory addresses. This made is possible for larger groups of humans to work together on the same computer program. This also made it possible to have larger and more ambitious programs.
It also brought new concerns:
programmers would “lose touch” with what the machine was actually doing, leading to inefficiencies and bugs due to mistaken assumptions on how their code was going to be translated into symbol space
the complexity of the system increased along with failure risks: the correct execution of a program went from its own correctness (and the correctness of the machine executing those instructions) to a more complex system in which a higher level program needed to trust that the compiler didn’t introduce hidden defects during the translation between spaces.
This transition happened so long ago (1957, to be exact) that today nobody effectively cares about these concerns (for better or worse). A clear signal this is the case is that today’s industrial software company (unless your job involves it) do not ask questions at the symbols space during interviews and focus their attention to evaluate candidates exclusively on the syntax and semantic space.
The Semantic → Syntax Bridge Before LLMs
Before AI assistance arrived at the scene, the only reliable semantic → syntax bridge available was human programmers.
Programming languages did evolve over time to make their syntax space more and more abstract and further separated from the symbol space (for example, object and aspect orientation, transparent memory management and garbage collection), which, in turn, made these programs easier to write and easier to reason about (even if often at the cost of performance and/or compiler/interpreter complexity).
Functional languages pushed the hardest in attempting to close the gap between syntax space and semantic space. The extreme composability of math was the north star: could one build a program by simply describing abstract concepts and letting the machines do everything else?
In practice, this was never very impactful. The most used programming languages in use today are procedural which means they tend to describe how the sequence of procedures is to be composed. More and more functional influences are permeating these languages (or their standard libraries) over time so the boundary is becoming more blurry, but the idea of programming directly in semantic space never really caught on despite decades of attempts.
The reason for this, IMO, has less to do with the level of abstraction of the concepts being composed in a program (which kept expanding over time) but rather with the rigidity of the descriptions. If a compiler returns a “syntax error” and it’s not able to dialog with me to resolve the misalignment, I’m still operating in “syntax space” even if the syntax is now describing higher level concepts.
The idea of feeding the picture of a whiteboard to a compiler and have it generate the code seemed laughable even to dream about (although executable UML did indeed try to achieve exactly that and failed as miserably as one expected).
The Semantic → Syntax Bridge After LLMs
As much as feeding a whiteboard picture to a compiler felt like sci-fi just a few years ago, today I routinely ask my coding assistant to read legacy code I know nothing about and draw me a box diagram of its internal modules and a sequence diagram of the interactions between them.
We never had machines that can help us bridge the semantic and syntax space and now we do. This feels to me as significant as the introduction of compilers.
Yet, I feel it is a mistake to believe that since now machines can bridge this last gap, we no longer need programmers or, even worse, that can we expect the same kind of disruption to apply to all aspects of knowledge work.
Why Software is Special
There are two fundamental reasons why building software is a special kind of knowledge work:
generally low capital intensity
generally fast try/fail cycles
The first means that you can start a company in a garage and the second means that you can evolve and adjust quickly and quickly understand if something work or doesn’t.
Compare this, for example, with biotech, aerospace or even electronic hardware manufacturing: all with high capital intensity (sometimes very high, like in silicon foundries) and with very slow try/fail cycles (sometimes very slow, like in human clinical trials).
Crucially, AI development itself no longer fits this profile: everything about its further development (from energy production, water consumption, datacenter bringup, silicon production and sourcing and compute allocation) has more “heavy industry” than “agile software” traits.
This is why, IMO, the idea of exponential AI self-improvements is laughable. If anything, scaling laws are pushing AI development further away from the cheap and fast operational dynamics which made software “eat the world”.
AI models are indeed software but their development dynamics are much more similar to the specialized silicon chips that powers them than Larry and Sergey’s legos web crawlers running in Susan’s garage.
English as a Programming Language
Bridging the semantic and syntax spaces makes it possible to generate output in syntax space by having a conversation with our robotic assistants in semantic space.
But it also makes it possible to write computer programs directly in English. This is effectively what Claude Skills are: computer programs that are written directly in English and are loaded on demand by agents when they need to learn about how to do something they don’t already know how to do.
But there is another sector in which English is used as a pseudo programming language: law.
One way to see the legal profession is programmers of a computation system that runs on somewhat well defined processes powered by humans brains running programs written in “legalese” (a somewhat artificial but generally self-consistent form of natural language) in order to obtain desired outcomes.
Looking at the legal profession this way might help us understand where AI can be a disruptor but also where it can’t be.
The first obvious part is “discovery” and “summarization”. Just like I ask my robotic assistants to read tons of code for me (no matter the programming language) and draw diagrams and distilled summaries, it is a sure thing to expect “legalese programmers” to benefit from the same abilities to scout vast quantities of “legalese” in various flavors and niche and draw up summaries and briefs quickly and relatively reliably.
But there are also structural differences. AI minions can make mistakes and invent stuff. For software code, that means compiler errors or failing tests. For lawyers, that means citing briefs that don’t exist and getting fined by judges and eroding trust in their colleagues and clients alike. The first can be fixed with “Claude Code” able to call the compiler and run the tests. “Claude Law” would need to be able to run a mock trial or phone a judge, something I feel very few lawyers would be willing to allow.
Moreover, lawyers have no access to the “symbol space” of the legal machine they are programming. Furthermore, the machine they are operating is inherently non-deterministic, which means they can’t write and execute tests on it.
Their try/fail cycles last forever compared to CI nightly runs and mistakes are highly irreversible. Computer programmers don’t go to jail (generally) when their production system fails. In fact, because of the need and benefit for unimpeded feedback, blameless post-mortem cultures have been established in most industrial settings, which means individual are protected and even encouraged to share information about what they did that caused an incident. As long as the damage wasn’t intentional, very few other professions can afford this level of blamelessness.
New Risks + New Opportunities
But there are also situations in which AI is not just making new bridges, but it’s also revealing new spaces.
Biology, for example. Deepmind’s work effectively solved “protein folding” and that can be seen as decoding the semantics of how sequences of amminoacids end up occupying space. It’s the closest thing we have seen to a “matter compiler” that takes sequences of code (effectively genetic “symbol space”) and creates reliably components of a machine.
It’s not hard to imagine further innovation down this path where a “sequence compiler” is able to get a description of the kind of high level operation we want to see performed and have the AI spits out the genetic sequence that would encode the proteins that would self-assemble to perform that action.
But it would also be easy to imagine a “Claude Biocode” tool that generates mRNA sequences just like Claude Code currently can generate x86 binary opcodes. The problem is not the ability to generate the sequences, the problem is the cost of understanding the risks/failures/costs of executing them!
Here is instructive to consider the tale of the Covid-19 mRNA vaccine: it took them only a few weeks to sequence the virus and make the mRNA sequence for the vaccine. A “Claude Biocode” would have maybe saved them a few days, but it still took us years to get a copy of that very same sequence injected into our bloodstream and reboot civilization worldwide. If that try/fail cycle was that long and that expensive even under such extreme societal pressure, imagine what it would be under normal circumstances. Claude Biocode wouldn’t make much of a difference there.
The larger point is that while frontier language models do change the energy landscape of knowledge work, sometimes dramatically, we must keep firmly in mind what are the forces at play that are the source of friction. Often, they are not related to the information itself, but they related to its applicability, to the necessary interaction with the real world or with other people.
We ignore the energy landscape in which the knowledge we work on operates at our own peril.