
On the Availability of Mechanical Reasoners
In which we discuss the recent advancements in neural System2 reasoners and try to extrapolate what that could mean for products designed to augment human intellect.

The biggest AI news of 2024 was the new (and yet to be released to the public) OpenAI o3 system achieving an impressive 87.5% score on the ARC-AGI-1 eval.
This is significant for two reasons:
ARC-AGI-1 is a “system2” pure-reasoning eval. It tests the ability of a system to observe something, understand it, abstract its internal consistency rules and apply them to a new task. What’s interesting about it is that humans generally perform well with it, while even the best publicly available AI systems struggle with it. The fact that OpenAI o3 scores well on that test is a sign that things are maturing not just in the “propriety of language” realm (which is effectively a solved problem now) but also in the “reasoning under constraints” realm (which is very much not).
While o3 did achieve those scores, the “cost per task” is eye watering. The system that achieved the best score spent around $5k per task.
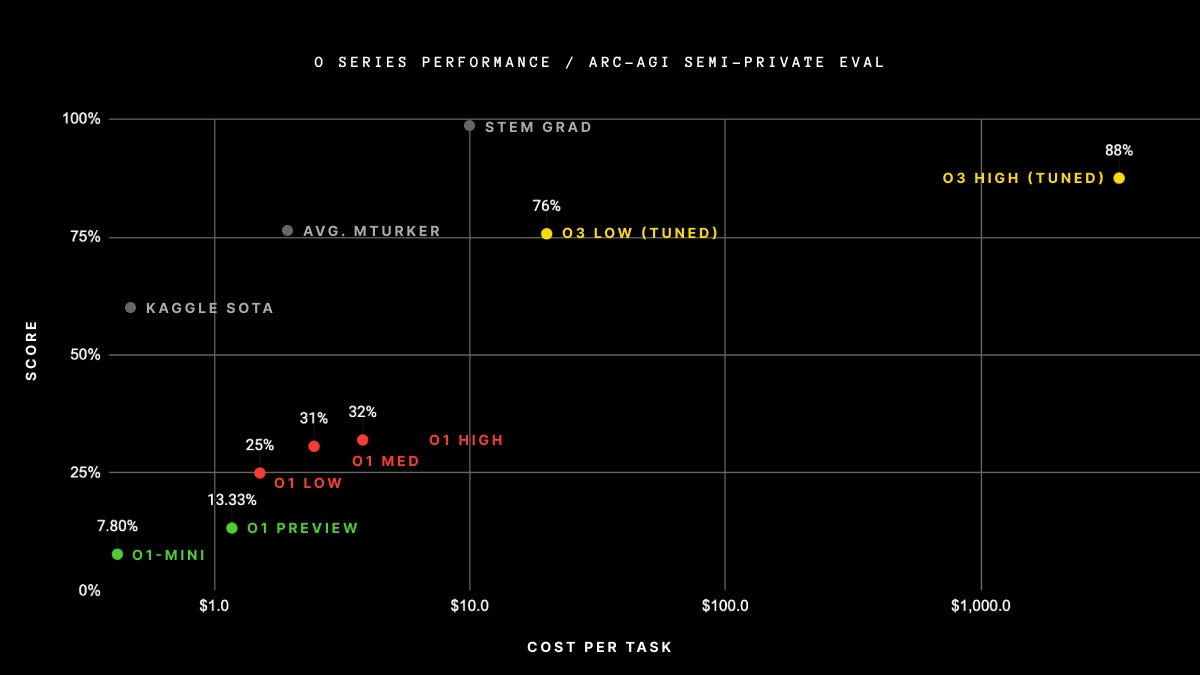
The above is the cost/score scatter plot for OpenAI systems performance in ARC-AGI. The three systems have been color-coded (green is o1 publicly available in preview, red is probably o1 with a lot more resources at its disposal and yellow is o3, which performance seems to indicate something different from o1 entirely).
But note the gray dots: those are humans. Kaggle and Amazon Mechanical Turk are “human computation” systems that allows one to pose challenges to human contractors who get paid to solve them. Kaggle contractors solve 60% of the tasks for pennies/task. Mturkers solved 75% of the tasks for around 3$/task. A STEM graduate achieves near perfect score (99%) for around $10/task. o3 scores 88% for $5k/task. That’s 13.5% worse score for 500x more money than humans specially trained for this kind of reasoning.
There is even something else here that is worth looking into. Here is one of the tasks that o3 “failed”:
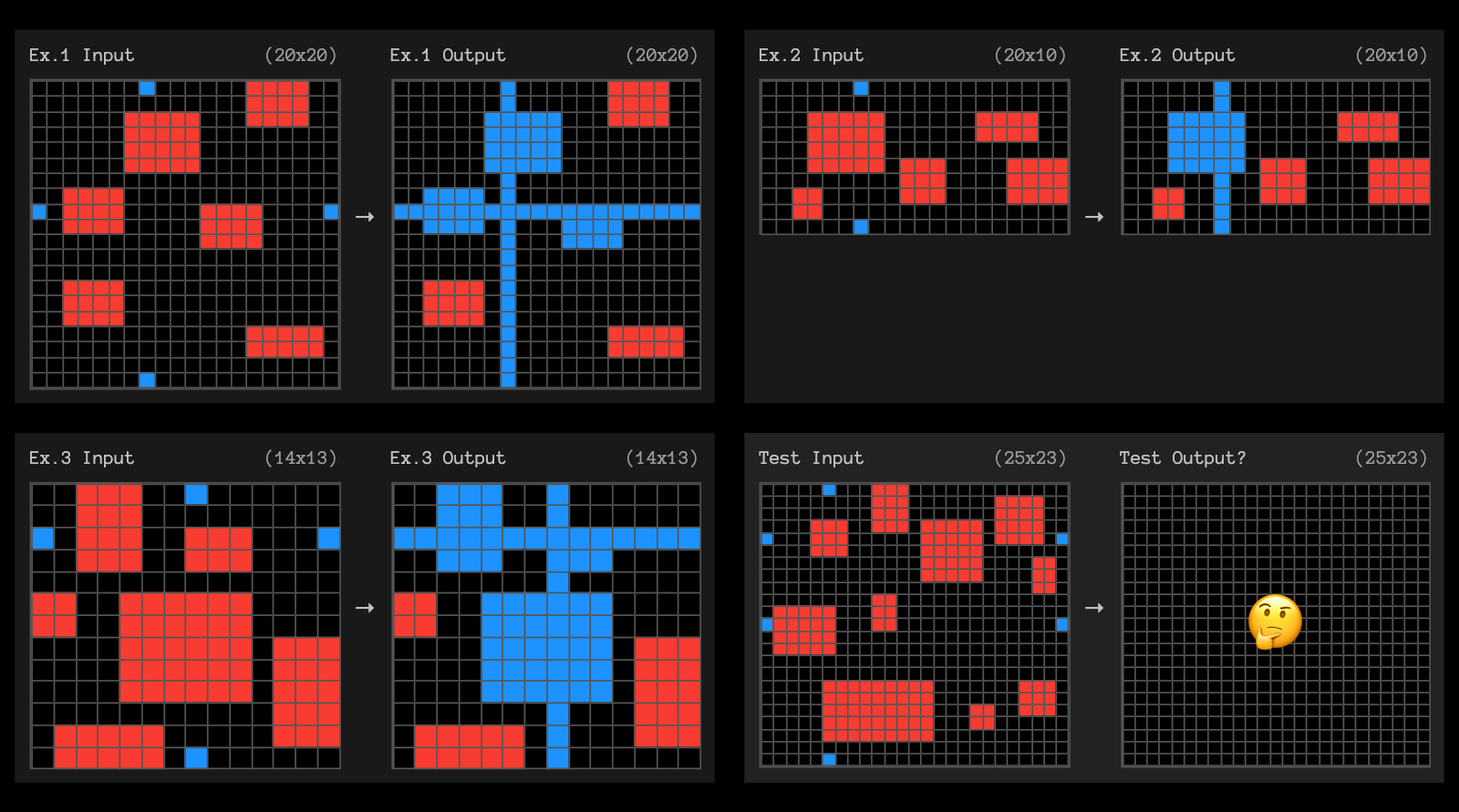
Can you solve it? What are the “latent rules” that you were able to emerge from the three examples?
o3’s solution was this
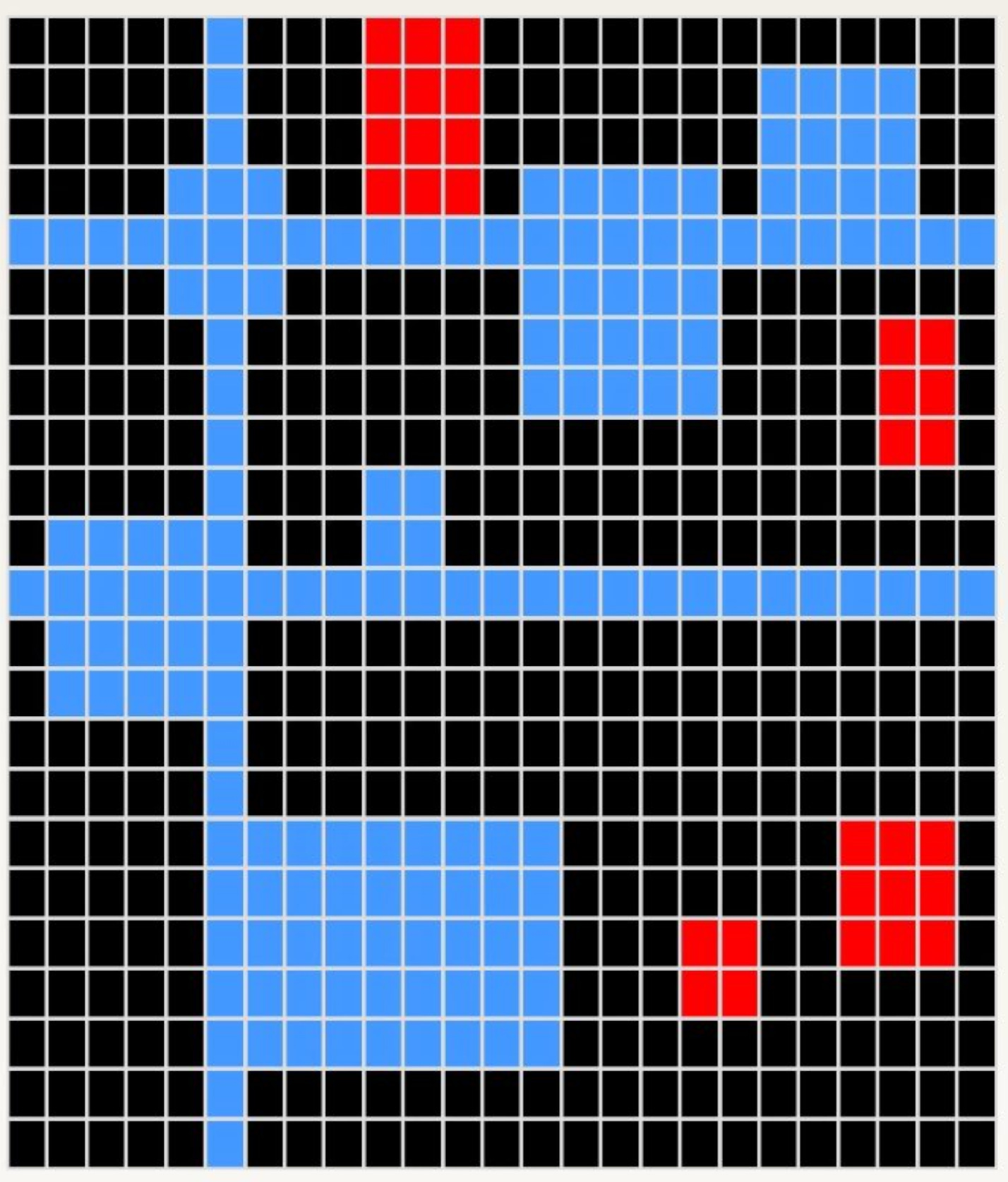
which was considered wrong because the top red rectangle was expected to be blue.
But if we look at the examples, there is nothing that specifies what to do with a rectangle that is touched but not intersected. Every example shows a line intercepting (as in overlapping) with existing rectangles. Choosing what to do with that top red rectangle that is merely being touched is unspecified. This particular task fails to test the ability of the solver to emerge rules from examples because it makes use of a rule (what to do with touched non-intersected rectangles) that is not present in the examples.
Now, don’t get me wrong: ARG-AGI-1 is superb work and a breath of fresh air in the generally vacuous AGI discussions. I point out this particular task not to rain on the ARG-AGI parade but to show the surprising utility of mechanical reasoners: they can even shed light into human reasoning biases (for example, why did all human STEM graduate felt the need to consider touching lines as coloring while the AI did not? that feels very interesting to me).
At the same time, “within technological reach” and “widely available” are not synonymous. At $5k/task with 88% success expectation is around 600x away from STEM graduates, which is completely impractical as a product.
I know what you’re thinking: 600x at 2x Moore’s law scaling per year is just ~9 years away. Not so fast, tho. Look at this plot of the cost per 100M gates (aka transistors) for different nodes (aka silicon manufacturing technologies) over time:
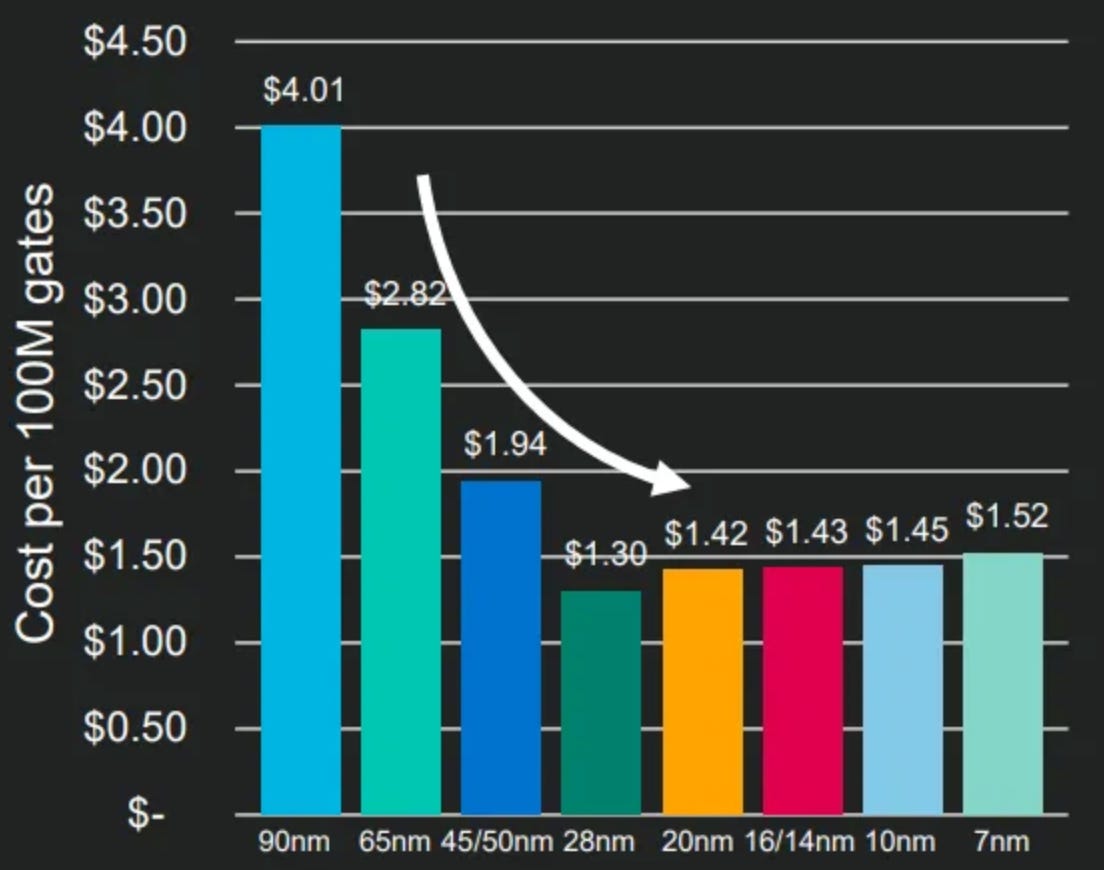
Moore’s law talks about “number of transistors per IC” but it doesn’t say anything about the cost of such transistors and those costs are now going up, not down. There are s-curves that are now reaching saturation, for example, look at these shown together here:
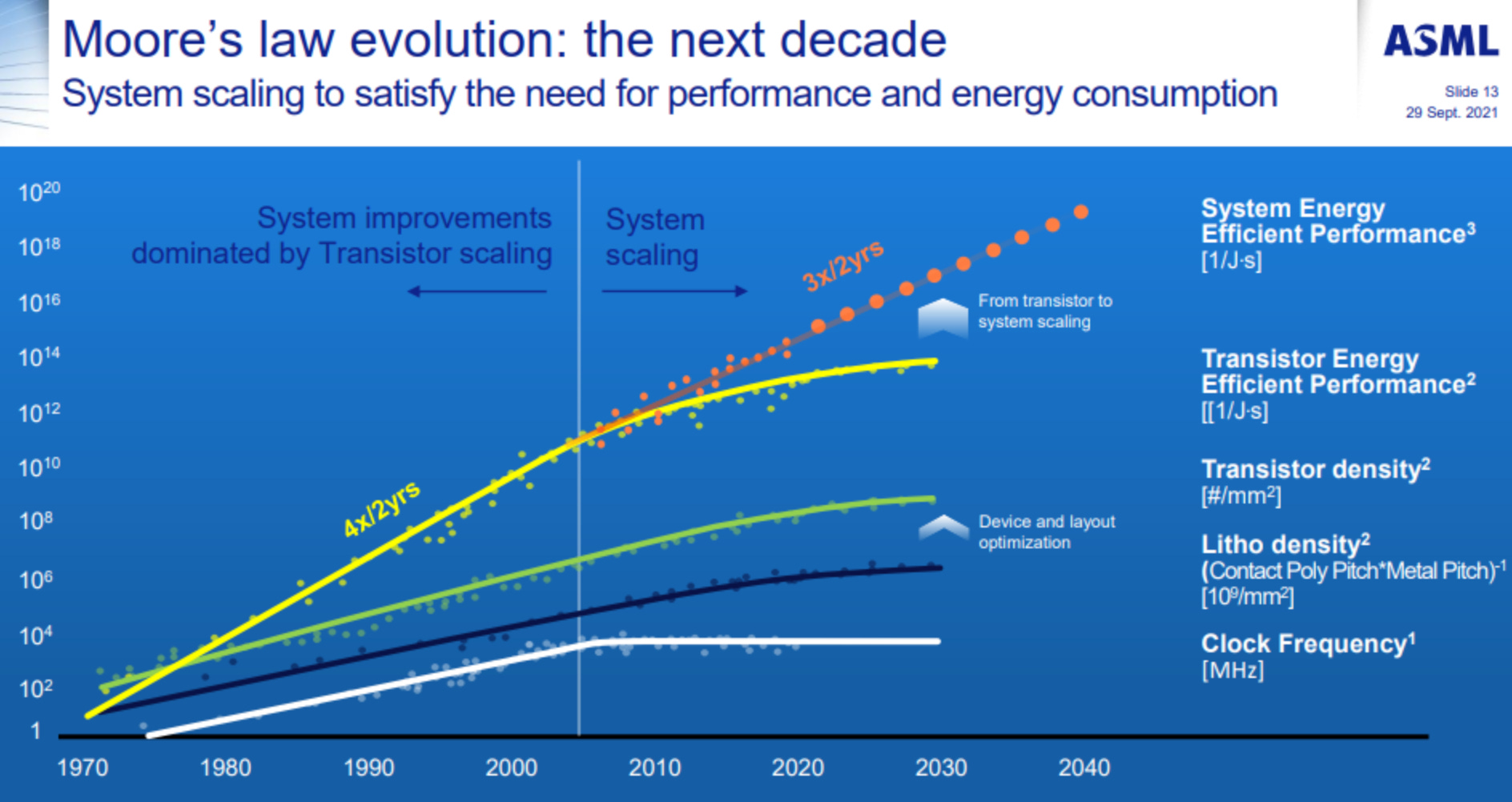
This is impacting everyone, even the ones executing well (TSMC+NVidia).
Here is the number of transistors per IC of the latest NVidia AI datacenter accelerators overlapped with Moore’s law trends (plot is mine) in which we can see that even the best of the pack is saturating:

One thing I heard is that some people believe there is only a factor of ~450x left in increasing computational performance of silicon. This includes nearly anything that exhibits any promise these days even with high manufacturing costs and risks (backside power delivery, gate-all-around transistors, 14A lithography, die-to-die optical interconnects, giant wafer-scale ICs, etc.).
Of course, it’s generally a bad idea to underestimate human ingenuity, especially in a field that has been able to re-invent itself continuously over so many decades, but we have seen those s-curves saturating and impacting the market (for example, Intel lost to AMD by failing to predict and account for the clock frequency ceiling). The laws of physics loom large when transistor gates are a few atoms wide.
So, let’s assume there is only 450x improvement coming from the silicon in the next decade or so (with, say, 10% per node increases in cost). What would that do to AI systems? That would bring o3 cost per task at 5000 * 1.1 * 1.1 * 1.1 / 450 ~= $15/task (assuming 3 different nodes 2nm, 18A and 14A).
$15/task is within the order of magnitude of the $10/task reported for STEM graduates so that would be impressive and that’s not even considering any architectural advancements of the models themselves… but $15/task is hardly “effectively free, as in cheaper to run inference on than the monetary value in advertising data on the user” as some believe.
In short: this shows me two things: machine reasoning is finally here but it’s also stupendously expensive for relatively simple tasks.
Ok, so what?
This stuff feels interesting to me because abstracting latent structure and operating within constraints seem to be the most glaring deficiencies of today’s AI systems. ARC-AGI-1 seems designed to show exactly that and progress here is significant and welcome.
For example, I work with coding assistants daily and while they have already replaced search engines as my go-to helping hand when I feel stuck, they are “vibe machines” in the sense that it’s pretty clear they don’t really understand what they are suggesting. Their utility feels significantly limited by this.
They are not really able to reason on the code they are suggesting and evaluate, for example, internal consistency. This is most notable when you ask them to extract novel patterns in code they have not being trained on. They are very good at assimilating and regurgitating patterns they have seen in their training corpora (where the internal consistency of the code was evaluated by human authors), but they are currently terrible at observing a new pattern, extracting the latent structure and operating on that latent structure to create a result that is internally consistent and operates within the boundaries of that latent structure (for example, GPT4o scores a pathetic 5% on ARC-AGI-1). This makes them not very useful when operating over large proprietary codebases. No amount of context size and RAG search quality would fix a model’s inability to reason within constraints.
I’ve come across of similar vibe-y people in my career: people that know all the acronyms, the patterns, the “surface” of the discourse but they don’t understand the “why” and they lack the curiosity, self-confidence or awareness to ask first principle questions. Their solutions feel derivative, flat and uninspired, even when do manage to work. In general, I find them to be poor thinking companions.
LLMs feel like that to me. They operate on the surface of the epistemic manifolds and while they are useful tools these days (they save me a ton of time summarizing and regurgitating things for me, even without understanding them), but they are not good cognitive sparring partners for things (software architecture, deep refactoring, risk management, planning, strategic thinking) that take up most of my brainpower, even when they doesn’t necessarily use a lot of my creativity or talent.
And yet, even assuming tremendous silicon and architectural improvements and widespread availability at $1/task with 90 sec runtime and 99% precision, would I use it? What kind of questions would I be asking it? Would I be able to recognize problems that require reasoning within constraints and pick the appropriate model and cost profile? Would a classifier be able to do that for me simply from the description of the task? or is this another halting problem?
Language is not intelligence and being good at language doesn’t make a system automatically good at reasoning. A lot of people can’t tell the difference between the two, which IMO shows why the hype around LLMs appears unstoppable even when the financials don’t add up.
Does better performance at System2 reasoning tasks change this equation and finally makes AI systems useful as general human cognition augmenters and amplifiers? I don’t know, but at $5k/task they are a mere scientific curiosity and not even product worthy. At $15/task in 10 years and $10T investments and lots of luck it also doesn’t seem that product-worthy either: back and forth seems to be a fundamental aspect of intermediated cognition and $15/task are a huge headwind to that.
This shows me light at the end of the tunnel of human cognitive augmentation, but it also suggests to me it’s time to stop hoping for scaling laws to save the day because it feels pretty clear at this point (at least to me) that they won’t.
Is this enough to burst the scaling-laws bubble, restart confidence that innovation is needed on the architectural front and that humans brains are not just very efficient gigantic transformers? I don’t know, but I sincerely hope it pushes in that direction.