

Is it peak GenAI yet?
Is it peak GenAI yet?
in which we try to observe the present from 25 years in the future and draw parallels between the current AI hype bubble and the "new economy" craze of the late 90's.

At the risk of dating myself, I was in my early 20’s when I got the first glimpse of what the web could be and immediately recognized its potential as transformative. While I had always liked computers since a very early age, networked computers were a whole different beast that I had not had access to before and seeing what one could do with them blew my mind. But the crucial ingredient that turned it into a frenzy was that web browsers make it obvious even to the technically uninitiated.
Between 1995 and 2000, the investment mania grew to crazy heights. The internet (the web was the internet) was going to change everything, it was going to be a “new economy”, untethered from physical constraints, with not just low marginal costs but effectively zero costs.
Between 1995 and its peak in March 2000, investments in the NASDAQ composite stock market index rose by 800%, only to fall to 78% from its peak by October 2002, giving up all its gains during the bubble.
We look back at this now with the same paternalistic sighs we reserve for memetic disturbances such as the Dutch tulip bulb mania of 1634 or the UK railway mania of 1846 which look absurd when seen from afar.
Just like Netscape showed the value of the web to the uninitiated, ChatGPT showed the value of machine learning and probabilistic computing.
Just like the internet which had been around and useful for the initiated for literally decades, machine learning had been doing the very same. Every ad targeted to us on a web site, every picture we take with our phones, every email that gets routed to spam automatically, every autocomplete on our phone keyboards, every alarm we tell our voice assistants in the kitchen to set with sticky hands, it’s all machine learning and has always been.
ChatGPT showed the world what we could do with probabilistic computing to the uncurious and uninitiated so it too created a frenzy. Now while camps debate whether AI is good or bad for you (AI boomers vs. doomers) the risk of missing out on this tech feels too great so the money pours in. The FOMO plus post-pandemic tech contraction is fuel for this fire. Now the question I ask myself is: where are we on the hype cycle?
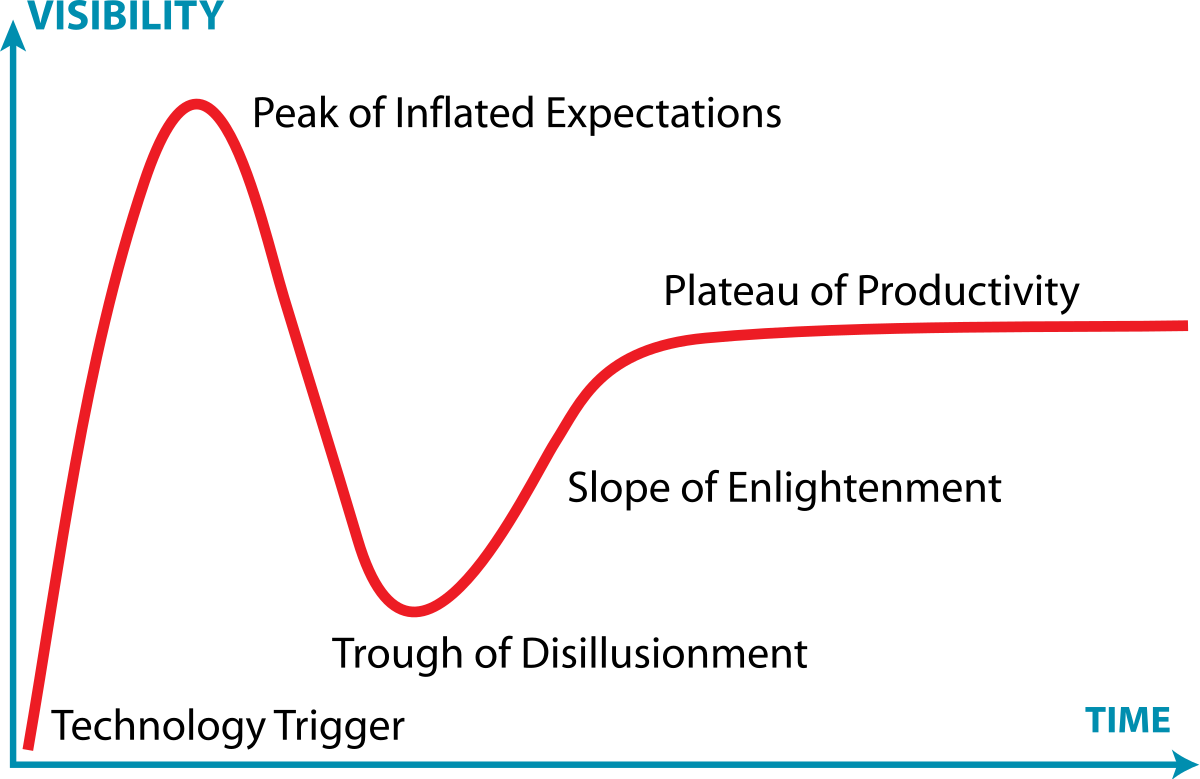
Have we reached the peak of inflated expectations yet? It is starting to feel to me like we are and I’ll elaborate as why.
Investments
If we look at it from the point of view of VC investments the peak was actually a few years ago:
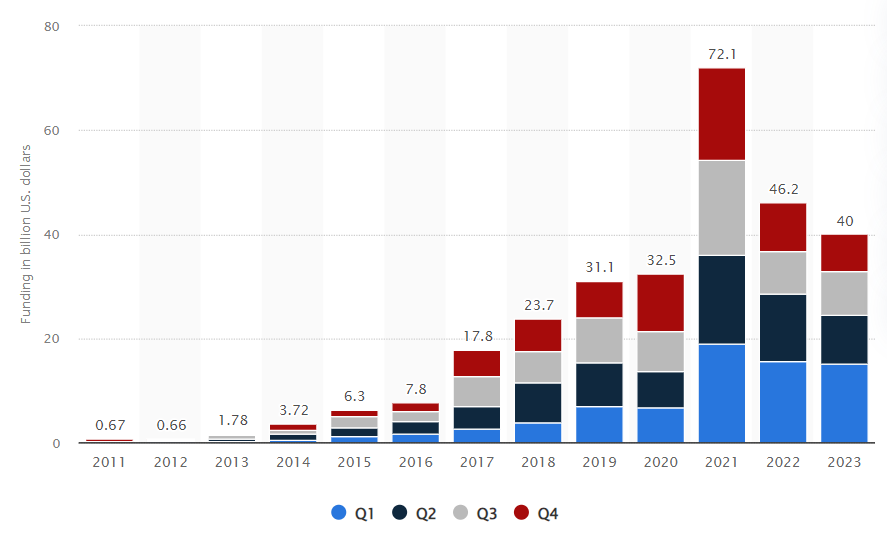
Now this plot comes from Statista and I have no way to validate its sources but having worked in and around ML while in Google Research around some of this period I can tell you that investment in this area would be substantially bigger if we include established technology companies.
Also, it doesn’t tell another side of the story: a lot of this funding is generally earmarked for cloud computing services. Microsoft with OpenAI and Amazon and Google with Anthropic. They managed to find a way to make a cost of expansion look like an investment in the balance sheet. What it doesn’t tell us is that investment into cloud expansion count as a success for the investor even if the startup fails. This suggests that we should be critical of these numbers in general as they might be capex masquerading as something else.
Moore’s law is not the point
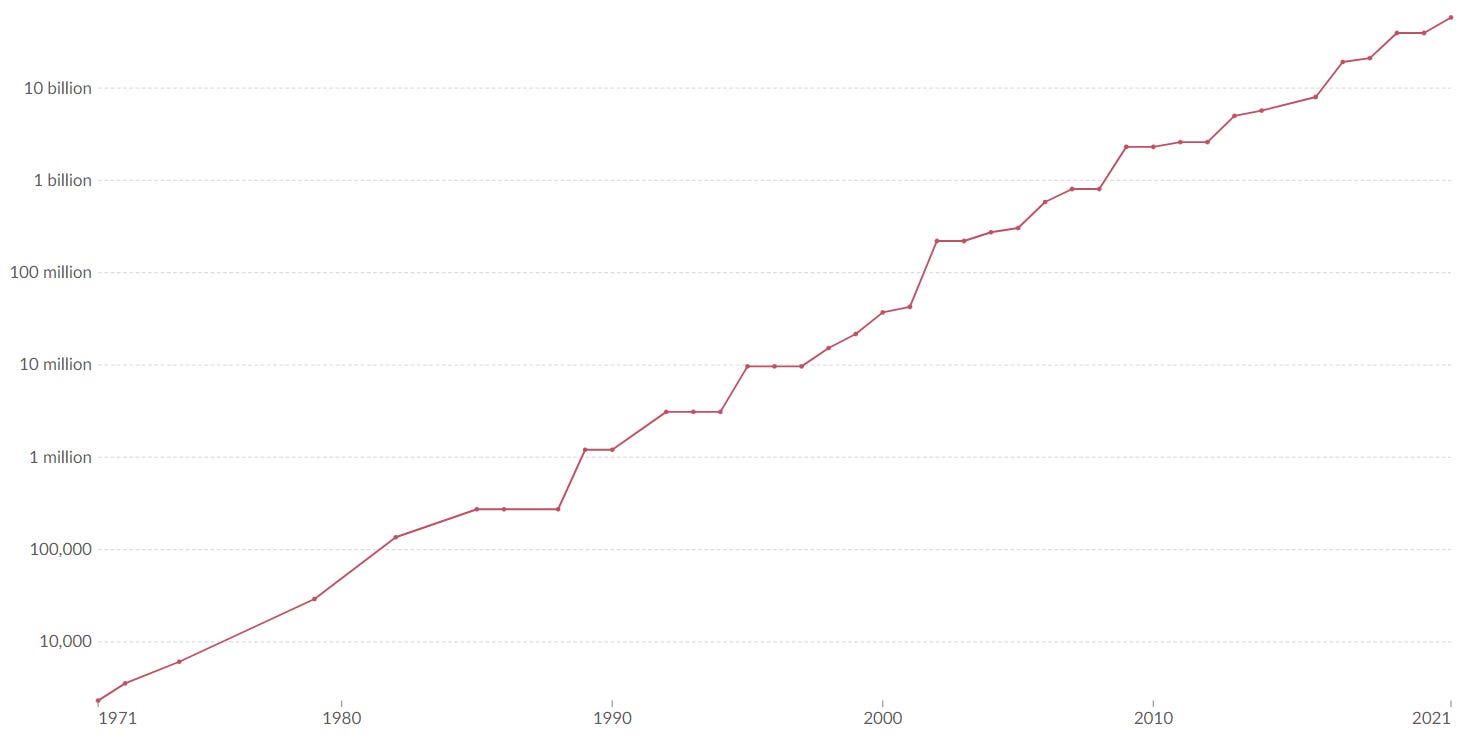
Moore’s law is the observation that the number of transistors in an integrated circuit (IC) doubles about every two years.
If you look at the plot it seems to continue to hold true all the way to recent years
but if you look at this from another dimension (cost per transistor) things start to look very different
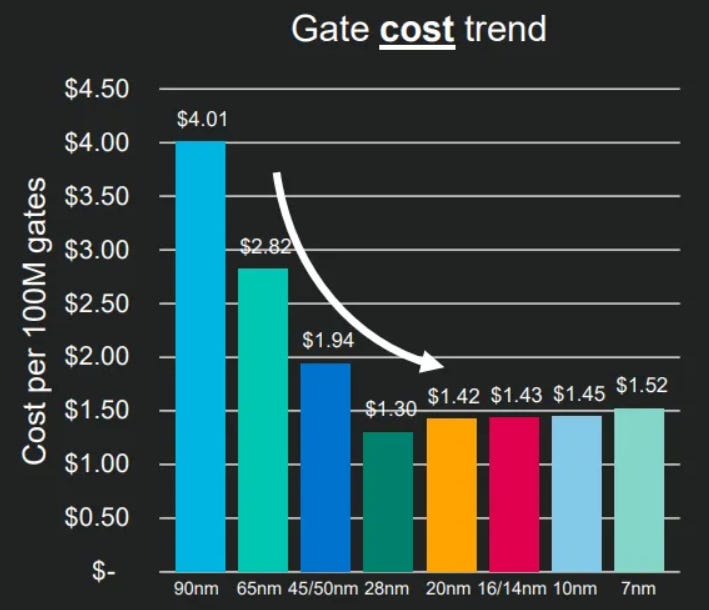
The 28nm node is the cheapest silicon manufacturing technology and it reached production capacity around 2011

That means that while new chips have more transistors they are also more expensive to produce: the cost per transistor is now consistently increasing.
Moreover, the cost and risk of manufacturing silicon chips with this density (3nm) is such that there is effectively only a handful of companies in the world can even afford to attempt to do it. GlobalFoundries is one that recently gave up.
There are only three companies in the world with enough skill, capital and ambitions to try to fab 3nm transistors: TSMC in Taiwan, Samsung in South Korea and Intel in the US. The fact that Intel itself is using TSMC to fab its Gaudi 3 AI accelerator show us that things are not going well for Intel at the foundry side.
Just to give a sense of the scale, a single silicon atom has a diameter of roughly 0.2 nanometers so a 3nm transistor gate is 15 atoms thick. Intel has recently done a major push to decouple itself from a vertical designer + foundry from two separate entities. Their 14a process (7 atoms across) is scheduled to arrive in 2027 but will require billions of dollars of investments. Nobody is holding their breaths, not even Wall Street and not even when the US taxpayer is footing a lot of this bill to reduce reliance on silicon manufacturing to what might end up being a warzone soon.
All in all this means one thing: AI accelerators are expensive and power hungry today and will remain expensive and power hungry tomorrow. Everyone in the information technology landscape is used to transistor size shrinkage as a way to reduce costs, increase speed, reduce power consumptions all in one neat clockwork package that comes every two years but that world died in 2011 and nobody really talks about it because the transition from desktop to mobile was in full swing and energy consumption was a much bigger factor than compute power. The only ones that noticed were avid gamers trying to get their hands on high-end GPUs and cryptocurrency miners who ended up taking most of the blame for scalping and compute scarcity.
But now look at this chart which represents the computational needs for machine learning models in FLOPS (floating point operations per second) over the entire history of machine learning:

The very interesting thing is that the end of transistor cost reduction and AlexNet (the model that propelled us into the deep learning phase of ML) happened around the same time (2011-2012). If we zoom into this area of the last 12 years:

we can see that AlphaGo started the trend of very large compute needs which grow with a factor of 3x a year. What’s even crazier is that now everybody thinks that “bigger is better” as far as ML is concerned so every other ML application is consuming compute at an even faster pace (5x/year).
This does not look sustainable to me even if China and Taiwan remain at peace.
The 70/30 problem
I wrote about this before but ML systems are probabilistic tools and not everyone understands what that implies. This very insightful article talks about how LLMs give an illusion of having a mind and responding properly to their queries because of the Forer/Barnum effect:
The tendency of people to rate sets of statements as highly accurate for them personally even though the statements could apply to many people.
By virtue of emerging statistical distributions straight from the data and being aligned to respond fairly and neutrally, LLMs effectively end up using the same techniques used by psychics, astrologers and con artists. Sam Altman is worried about it:
So now we have system that are probabilistic, overconfident, self-unaware and superhuman in the ability to persuade users of their capacities, even when they don’t have them. I’m not worried at all about these things turning into Skynet, but I am very much worried about how intrinsically overpromising this technology is.
I have seen AI-based solutions absolutely nail 70% of a problem space with a single talented engineer, some glue code and some cloud APIs in a few days. Just 10 years ago, an expert would have forecasted the need for a team of 100 engineers and a decade of work. This is nothing short of amazing in terms of capacity amplification and very much fuels the hype and the investment craze.
But it also has this amazing property of hiding the fact that that 30% of the solution space is effectively uncovered and behaving VERY differently from the first 70%(Dimitri wrote about this as well, although he goes in a different direction with it).
We don’t really know how to work with these systems and, more importantly, we don’t know how to forecast how much effort will need to go into covering that 30% when that 70% took so little effort. Even the technically initiated have trouble forecasting the effort to bridge these gaps and I feel that a LOT of AI startups will die trying to bridging that gap. My fears is that a lot of lessons learned will die with them.
System 2 blindness
Which leads me to the crux of the matter for me: the current batch of LLMs spend a fixed amount of computation for each token they produce. Unless this amount of compute is enormous (which we know can’t happen because of silicon scaling issues thus power issues), this fact alone tells you that LLMs can’t be smart enough to provide solutions that automatically bridge the 30% gap because they don’t know how to spend more time thinking on something.
Yann Lecun does a very good job explaining why that’s a problem.
When we think about something, there are things that come naturally and there are things that take time and thought and effort. LLMs can’t do both. They are effectively vibe machines which are generally terrible at operating within constraints. Ask it to book a flight from city A and city B and without appropriate supervision it might have you land after your coincidence takes off, or in a different airport altogether!
Everyone is talking about how we’ll have AGI in a decade but that feels to me like the promise of nuclear fusion being 10 years away for the last 50. Endless funding opportunities if it’s just around the corner but we never need to show it working.
Personally, I feel that scale alone can’t solve this problem and we need different architectures, but the siren song of “just add more dimensions to the embeddings, more attention heads, more context and more layers” is just so appealing and “in context learning” such a crutch that separating the wheat from the chaff in this space feels challenging.
Buildout
In her book Technological Revolutions and Financial Capital, Carlota Perez highlights a lifecycle of technological revolutions (see this great post about it by Ben Thomson that goes into more details). One important part of her model is that cycles overlap and the collapse of the frenzy stage leaves excess capacity in the form of infrastructure buildout that finds itself beyond capacity.
For the .com crash, the extra buildout was networking equipment. Enron and WorldCom imploded and Cisco shed most of its stock value
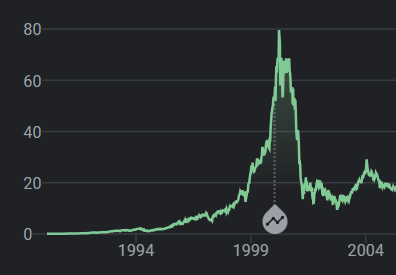
Doesn’t that remind you of something? Ah yes, NVidia stock today
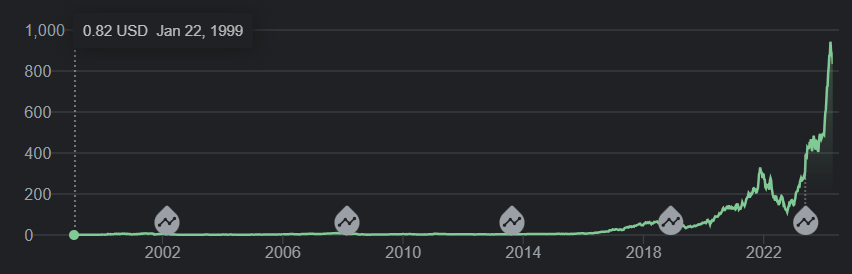
Everyone is racing to build and deploy AI accelerators in datacenters. Sometimes they are even taking over the buildout and the excess capacity left over by the implosion of cryptocurrencies ventures that went belly up. That feels like a very good thing to me as that that kind of compute seems more useful.
The networking buildout of the end of the 90’s gave us the interconnectivity infrastructure on top of which today’s modern world and tech economy is based on.
I don’t know what the compute buildout of the bursting GenAI bubble will bring but if it’s anything like these last 20 years it will be very interesting to watch.